Abstract
具有数百万个参数的深度神经网络可能由于过拟合而泛化能力较差。为了缓解这个问题,我们提出了一种新的正则化方法来惩罚相似样本之间的预测分布。特别地,我们在训练过程中提取同一标签的不同样本之间的预测分布。这使得单一网络(即自我认知蒸馏)的黑暗知识(即关于错误预测的知识)规范化,迫使它以一种分类的方式产生更有意义和更一致的预测。因此,它减轻了过度自信的预测,并减少了内部阶层的变化。在各种图像分类任务上的实验结果表明,该方法简单而功能强大,不仅能显著提高现代卷积神经网络的泛化能力,而且能提高其标定性能。
Introduction
深度神经网络(dnn)在许多计算机视觉任务上都取得了最先进的性能,如图像分类[19]、生成[4]和分割[18]。随着训练数据集规模的增加,dnn的规模(即参数的数量)也会随之增大,以有效地处理如此大的数据集。然而,具有数百万个参数的网络可能会出现过拟合和泛化能力差的问题[36,55]。为了解决这一问题,文献中研究了许多正则化策略:早期停止[3]、L1/ l2正则化[35]、dropout[42]、批量归一化[40]和数据增广[8]。
正则化dnn的预测分布是有效的,因为它包含了最简洁的模型知识。在这方面,文献中提出了标签平滑[32,43]、熵最大化[13,36]和基于角度边缘的方法[5,58]等策略。在解决网络标定[16]、新颖性检测[27]、强化学习探索[17]等相关问题上也有一定的影响。在本文中,我们利用黑暗知识[22]的概念,即dnn对错误预测的知识,开发一种新的深度模型输出正则化器。它的重要性首先由所谓的知识蒸馏(KD)[22]得到证明,并在随后的许多著作中得到研究[1,39,41,54]。
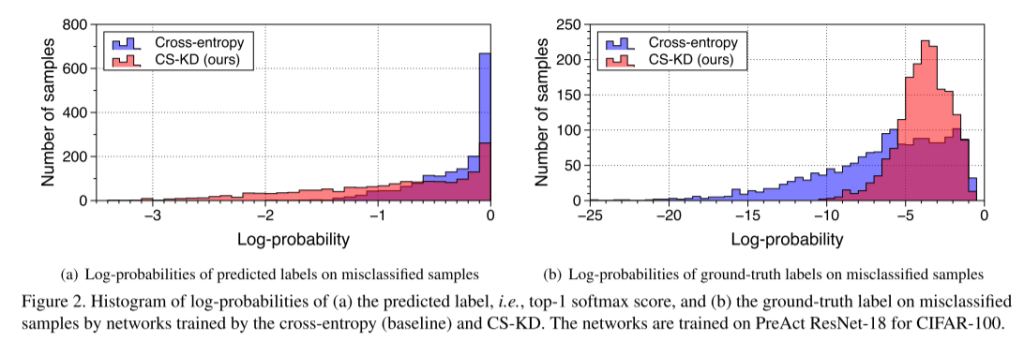
而相关著作[15,21]利用知识蒸馏的方法将教师网络中所学到的黑暗知识转移到学生网络中,我们在训练单一网络的过程中对黑暗知识本身进行了规则化,即自我知识蒸馏[53,57]。具体来说,我们提出了一种新的正则化技术,称为类自知识蒸馏(CS-KD),它匹配或蒸馏dnn在相同标签的不同样本之间的预测分布,如图1(a)所示。
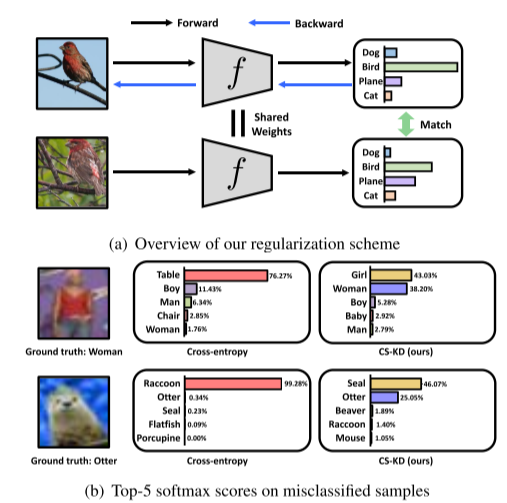
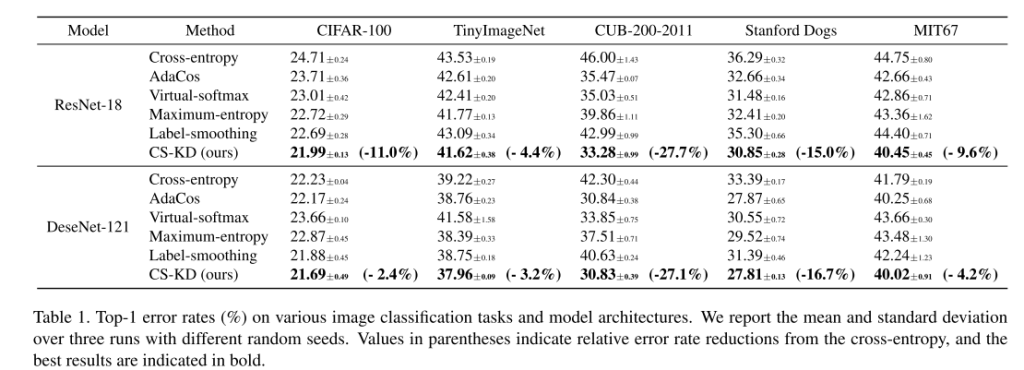
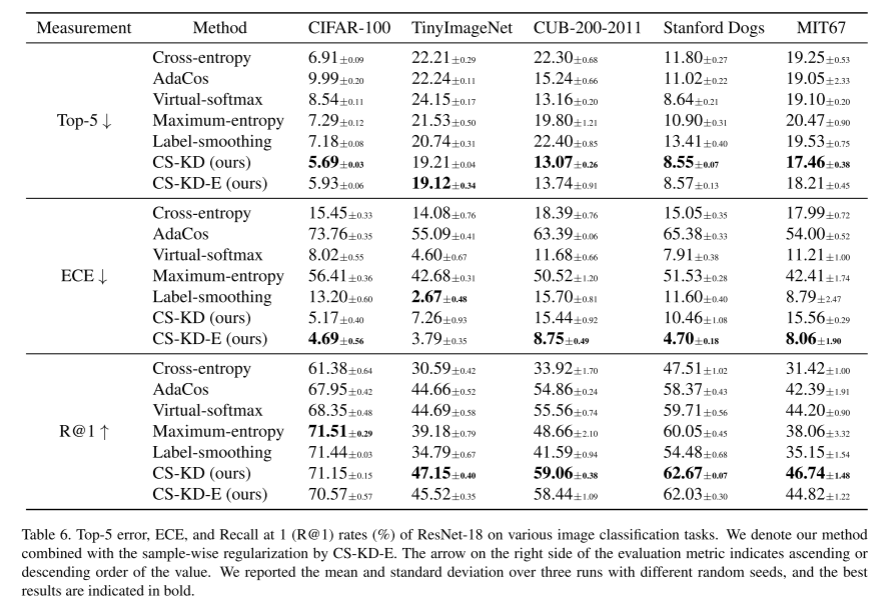
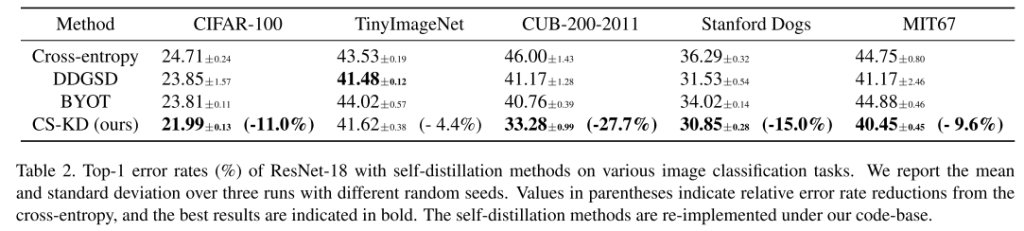
可以预期,本文提出的正则化方法迫使dnn在样本属于同一类的情况下产生类似的错误预测,而传统的交叉熵损失没有考虑预测分布上的这种一致性。此外,它可以同时实现两个理想的目标:防止过度自信的预测和减少阶级内部的变化。我们注意到,文献中已经通过不同的方法对它们进行了研究,即分别是熵正则化[13,32,36,43]和基于边缘的方法[5,58],而我们使用单一的原则来实现这两种方法。我们使用深度卷积神经网络证明了我们简单而强大的正则化方法的有效性,例如ResNet[19]和DenseNet[23]训练用于各种数据集上的图像分类任务,包括cifa -100[26]、TinyImageNet1、CUB-200-2011[46]、Stanford Dogs[25]、MIT67[38]和ImageNet[10]。在我们的实验中,我们的方法的前1错误率始终低于先前的输出正则化方法,如基于角边缘的方法[5,58]和熵正则化方法[13,32,36,43]。特别是前5个错误率和预期校准误差[16]的增益总体上更大,这证实了我们的方法确实使预测分布更有意义。我们还发现,我们的方法的前1位错误率总体上低于最近的自蒸馏方法[53,57]。此外,我们通过将我们的方法与其他类型的正则化方法相结合来提高性能,例如Mixup正则化[56]和原始的KD方法[22],来研究我们的方法的变体。例如,我们在ResNet-18和ResNet10下使用CUB-200-2011数据集,将Mixup的top-1错误率从37.09%提高到30.71%,KD的错误率从39.32%提高到34.47%。
我们注意到在文献[2,7,24,31,37,44,53]中已经研究了使用一致性正则化器的想法。以往的方法都是将原始输入和扰动输入的输出分布进行正则化,使之趋于相似,而我们的方法则要求具有同一类的不同样本之间的一致性。据我们所知,还没有研究过这样一种基于类的正规化。我们认为,本文提出的方法可能会在其他应用中获得更广泛的应用,例如人脸识别[11,58]和图像检索[45]。
Class-wise self-knowledge distillation
我们注意到在文献[2,7,24,31,37,44,53]中已经研究了使用一致性正则化器的想法。以往的方法都是将原始输入和扰动输入的输出分布进行正则化,使之趋于相似,而我们的方法则要求具有同一类的不同样本之间的一致性。据我们所知,还没有研究过这样一种基于类的正规化。我们认为,本文提出的方法可能会在其他应用中获得更广泛的应用,例如人脸识别[11,58]和图像检索[45]。2. 在本节中,我们介绍了一种新的正则化技术——类自认识蒸馏(CSKD)。在本文中,我们将重点放在完全监督分类任务上,并将x∈x表示为输入,y∈y ={1,…, C}作为它的基本真理标签。假设使用softmax分类器对一个后验预测分布进行建模,即给定输入x,预测分布为:
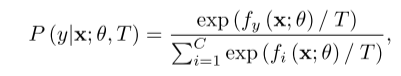








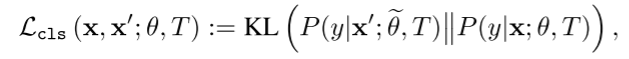
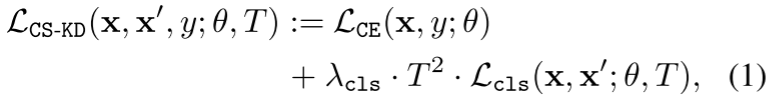





Comments | NOTHING