参考资料:
CVPR2022 | 通过目标感知Transformer进行知识蒸馏 - 掘金 (juejin.cn)
(53条消息) RMIT&阿里&UTS&中山提出Target-aware Transformer,进行one-to-all知识蒸馏!性能SOTA_我爱计算机视觉的博客-CSDN博客
《Knowledge Distillation via the Target-aware Transformer》笔记 - 知乎 (zhihu.com)
Abstract
知识蒸馏成为提高小型神经网络性能的实际标准。以往的方法大多提出以一对一的空间匹配的方式将教师的表征特征从教师回归到学生。然而,人们往往忽略了这样一个事实,即由于架构的差异,在同一空间位置上的语义信息通常是不同的。这极大地破坏了一对一蒸馏方法的基本假设。为此,我们提出了一种新的一对一空间匹配知识蒸馏方法。具体来说,我们允许教师特征的每个像素被提取到学生特征的所有空间位置,给定它的相似性,这是由一个目标感知的变压器生成的。我们的方法在各种计算机视觉基准上都大大超过了最先进的方法,如ImageNet,Pascal VOC和COCOStuff10k
代码链接:sihaoevery/TaT (github.com)
1. Introductio
为了计算上述方法的蒸馏损失,需要从教师中选择源特征图,从学生中选择目标特征图,其中这两个特征图必须具有相同的空间维度。如图1 (b)所示,以一对一的空间匹配方式计算了损失,它被表示为在每个空间位置上的源和目标特征之间的距离的总和。这种方法的一个基本假设是,每个像素的空间信息都是相同的。在实践中,由于学生模型通常比教师的卷积层少,这个假设通常无效的。图1 (a)显示了一个例子,即使在相同的空间位置,学生特征的接受域往往明显小于教师的,因此包含的语义信息较少。此外,最近的研究证明了接受域对模型表示能力的重要性。这种差异是当前一对一匹配蒸馏导致次优结果的一个潜在原因。
 图1.语义不匹配的说明。假设老师和学生分别是3层和2层的对流网,内核大小为3×3,步幅为1×1。(a)显示了最终特征图的中间像素的接受域,其中蓝色框代表老师的接受域,橙色框代表学生的接受域。由于教师模型具有更多的卷积操作,因此生成的教师特征图具有更大的接受域,从而包含了更丰富的语义信息。(b)因此,以一对一的空间匹配方式直接回归学生和教师的特征可能是次优的。(c)我们提出了一种通过目标感知变压器的一对一知识蒸馏,它可以让教师的空间成分被蒸馏到整个学生特征图。
图1.语义不匹配的说明。假设老师和学生分别是3层和2层的对流网,内核大小为3×3,步幅为1×1。(a)显示了最终特征图的中间像素的接受域,其中蓝色框代表老师的接受域,橙色框代表学生的接受域。由于教师模型具有更多的卷积操作,因此生成的教师特征图具有更大的接受域,从而包含了更丰富的语义信息。(b)因此,以一对一的空间匹配方式直接回归学生和教师的特征可能是次优的。(c)我们提出了一种通过目标感知变压器的一对一知识蒸馏,它可以让教师的空间成分被蒸馏到整个学生特征图。
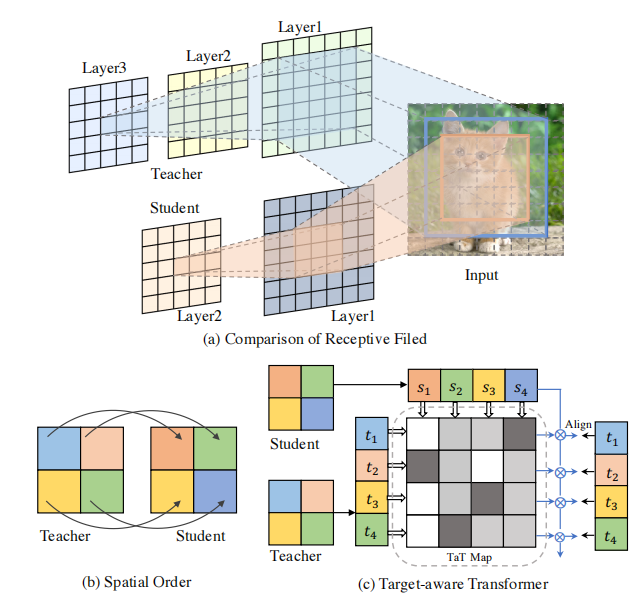
为此,我们提出了一种新的一对一空间匹配知识精馏方法。在图1 (c)中,我们的方法通过参数相关性将教师在每个空间位置的特征提取为学生特征的所有组成部分,即蒸馏损失是所有学生组成部分的加权总和。为了建模这种相关性,我们制定了一个变压器结构,重构重建学生特征的相应个体成分,并与目标教师特征对齐。我们称之为目标感知变压器。因此,我们使用参数相关性来测量基于学生特征和教师特征的表征成分的语义距离,来控制特征聚合的强度,这解决了一对一匹配知识精馏的缺点。
由于我们的方法计算特征空间位置之间的相关性,当特征图较大时,可能会变得难以处理。为此,我们以两步分层的方式扩展了我们的管道:
- 我们不是计算所有空间位置的相关性,而是将特征映射分成几组补丁,然后在每一组内进行一对一的蒸馏;
- 我们进一步将一个补丁内的特征平均为一个向量来提取知识。这通过数量级降低了我们的方法的复杂性。
我们的贡献可以总结如下:
- 论文提出通过目标感知的transformer进行知识蒸馏,使得整个学生能够分别模仿教师的每一个空间组件。通过这种方式,论文可以提高匹配能力进而提高知识蒸馏的性能。
- 论文提出分层蒸馏法,将局部特征与全局依赖性一起转移,而不是原始的特征图。这使得论文能够将所提的方法应用于因特征图的大尺寸而承担沉重的计算负担的应用。
- 通过应用论文的蒸馏框架,与相关的替代方案相比,论文在多个计算机视觉任务上实现了最先进的性能。











Comments | NOTHING