原文
Abstract
知识蒸馏(KD)是一种流行的技术,以转移知识从教师模型或集合到学生模型。它的成功通常归因于关于教师模型和学生模型的班级分布或中间特征表示之间的相似性/一致性的特权信息。然而,直接推动学生模型模仿教师模型的概率/特征,在很大程度上限制了学生模型学习未被发现的知识/特征。
在本文中,我们提出了一种新的继承和探索知识蒸馏框架(IE-KD),其中将学生模型分为继承和探索两个部分。继承部分以相似性损失学习,将现有的学习知识从教师模型转移到学生模型,而鼓励探索部分学习不同于继承的具有不相似性损失的表示。我们的IE-KD框架是通用的,可以很容易地与现有的蒸馏或相互学习方法结合来训练深度神经网络。大量的实验表明,这两部分可以共同推动学生模型学习更多样化和有效的表示,我们的IE-KD可以作为改进学生网络以实现SOTA性能的通用技术。此外,通过将我们的IE-KD应用于两个网络的训练,可以提高两个w.r.t.的性能深度的相互学习。
IE-KD的代码和模型:
https: //github.com/yellowtownhz/IE-KD
aliyun/Revisiting-Knowledge-Distillation-an-Inheritance-and-Exploration-Framework (github.com)
1. Introduction
知识蒸馏是将知识从一个网络(教师)转移到另一个网络(学生)的最流行的方法之一。Hinton等人[10]首先提出,将知识从一个大型教师网络(或整体)转移到一个更容易部署的小型学生网络。它的工作原理是训练学生预测目标分类标签和模拟教师的班级概率,因为这些特征包含了关于教师如何倾向于概括[10]的额外信息。所有最近的蒸馏工作都遵循这种哲学,即在班级概率或教师网络和学生网络的中间表示之间进行额外的一致性控制。KD [10]和Tf-KD [32]主要关注输出类概率的一致性。在[33]、AB [13]、FT [16]、OD [12]、FEED [22]和FitNet [24]上,对中间特征提出了不同的一致性控制。FSP [31]提出了一种对中间特征内部相似性的一致性控制方法。总之,所有最近的蒸馏方法在学生模型和教师模型之间的一致性度量上都存在差异。
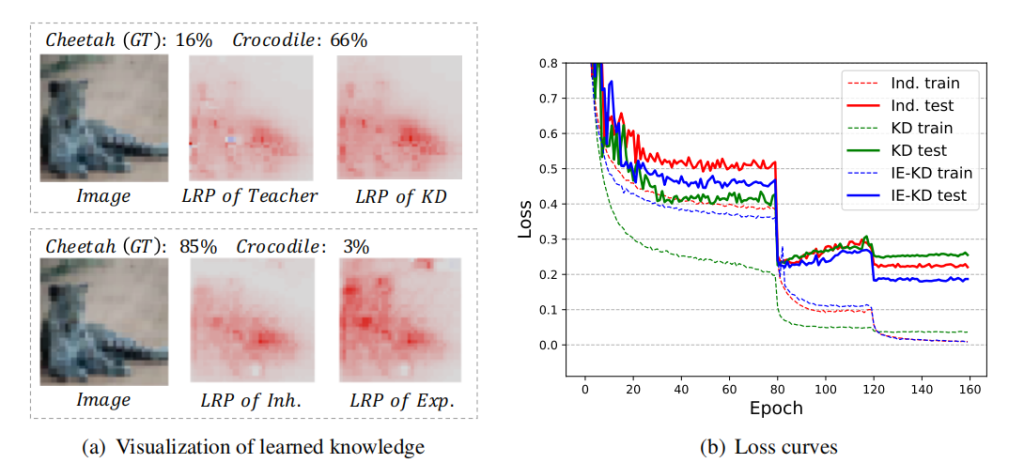
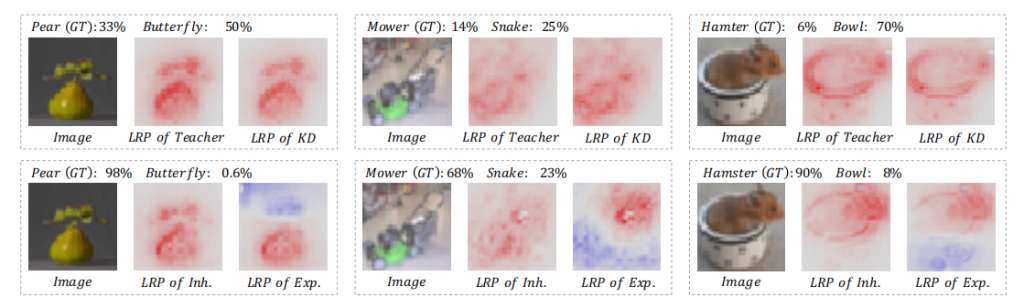
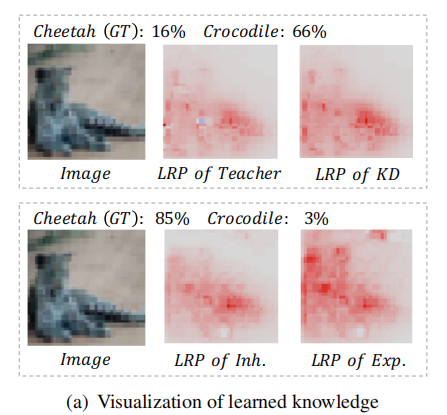
然而,直接推动学生模型模仿教师模型的概率/特征,限制了学生模型学习新的知识/特征。如图1(a)所示,与训练良好的教师相比,使用KD训练的学生模型学习到的是非常相似的模式(更多的结果将在补充材料中显示)。在这种情况下,“猎豹”被误诊为“鳄鱼”的教师模型也被KD训练的学生模型错误分类。该模型将其大部分预测归因于“猎豹”的尾巴,它类似于一条“鳄鱼”。因此,学生网络没有在耳朵和嘴上加入新的相关模式,这对“猎豹”和“鳄鱼”有很大的区别。因此,我们需要一种机制来找到更有用的特征,以正确的预测被教师网络忽略。
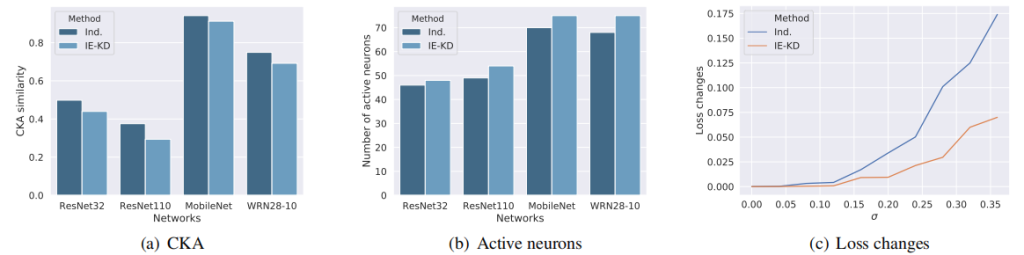
 图1。左:学习到的知识可视化分类,包括教师网络(教师的LRP)、KD训练的学生网络(KD的LRP)、IE-KD的继承部分(Inh的LRP)。以及IE-KD的勘探部分(Exp.的LRP)。LRP [21]通过可视化像素对分类的贡献来解释网络。右图:在学生网络(ResNet-56)的CIFAR-10上的训练损失(虚线)和测试损失(粗线),这是通过独立学习(从头开始训练)、KD和IE-KD(使用ResNet-20作为教师网络)进行训练的。为了进行公平的比较,KD和IE-KD在这里对应于FT和IE-FT。直接推动学生网络模拟教师网络的输出,限制了学生网络学习新知识。当学生网络大于教师网络时(同时培训和考试损失较高),甚至会导致一个糟糕的解决方案。
图1。左:学习到的知识可视化分类,包括教师网络(教师的LRP)、KD训练的学生网络(KD的LRP)、IE-KD的继承部分(Inh的LRP)。以及IE-KD的勘探部分(Exp.的LRP)。LRP [21]通过可视化像素对分类的贡献来解释网络。右图:在学生网络(ResNet-56)的CIFAR-10上的训练损失(虚线)和测试损失(粗线),这是通过独立学习(从头开始训练)、KD和IE-KD(使用ResNet-20作为教师网络)进行训练的。为了进行公平的比较,KD和IE-KD在这里对应于FT和IE-FT。直接推动学生网络模拟教师网络的输出,限制了学生网络学习新知识。当学生网络大于教师网络时(同时培训和考试损失较高),甚至会导致一个糟糕的解决方案。
直观地说,简单地模仿教师网络的输出将缩小学生网络的最优参数的搜索空间,并导致从特征学习的观点的糟糕的解决方案。
此外,我们发现,当将知识从一个小的教师网络转移到一个大的学生网络时,这种现象变得更加明显(如图1(b)所示)。根据[1,5]的观察,小网络通常与大网络一样具有足够的容量,但以更简洁的方式表示特征[24]。因此,大型网络不仅要用一些参数来模拟这种紧凑的表示,以减少自身的冗余,还要解放其他参数,探索更多不同和互补的特征,以提高其多样性和泛化能力。在上述分析的基础上,本文提出了一种新的继承和探索知识蒸馏框架(IE-KD),通过部分跟踪教师网络中的知识,部分探索与教师网络互补的新知识来训练学生网络。
在我们的IE-KD中,知识是通过一致性和多样性这两个原则来传递的。一致性确保了在教师网络中编码的良好学习到的知识被学生网络成功地继承。多样性确保了学生网络能够探索与继承的特征互补的新特征。IE-KD的动机来自进化中的遗传理论。遗传力涉及到性状的遗传和变异。进化是自然选择作用于种群多样性的结果,这最初源于突变。进化有三个关键因素:
- 从父母那里继承了紧凑和有效的性状由基因编码,
- 由基因突变产生的新的多样化基因型,
- 压力环境下的自然选择。
在此基础上,我们将学生网络分为两部分:一部分通过一致性/遗传损失(相似性)继承了教师网络中由因素编码的紧凑而有效的知识,另一部分通过多样性/探索损失(不相似性)推动生成不同的特征。监督任务(分类/检测)损失扮演着自然选择的作用,引导探索部分收敛到多样化而有效的特征。
IE-KD的另一个密切相关的动机来自于对Q-learning中行为的探索[20],和流行的AlphaGo [26],一半的行动遵循政策网络的预测,和另一半随机抽样从剩余的行动空间,确保足够的探索状态空间。此外,[4]提出了一种类似形式的损失函数来攻击一个白盒DNN的热图,使其注意力集中在图像的其他区域。受这些见解的启发,我们提出了我们的IE-KD框架,通过探索除了教师学习的知识之外的新的和未被发现的知识,来改善学生网络的培训。
QL:强化学习:Q-learning由浅入深:简介1 - 知乎 (zhihu.com)
总的来说,我们的IE-KD框架是通用的,可以很容易地与现有的蒸馏或相互学习方法结合来训练深度神经网络。大量的实验表明,这两部分可以共同推动学生模型学习更多样化和有效的表示,我们的IE-KD可以作为改进学生网络以实现SOTA性能的通用技术。此外,通过将我们的IE-KD应用于培训对于两个网络,两者的性能都可以提高w.r.t.深度的相互学习。
2. Related Work
在本文中,我们主要关注网络之间的知识转移。所有相关工作可分为三种类型:
- 从预先训练好的教师网络通过蒸馏到学生网络的一致性控制
- 通过一致性控制同步学习网络对
- 以及通过教师自由正则化的自蒸馏。
一致性控制从一个预先训练过的教师网络或集合到一个学生网络。有各种各样的方法可以将知识从预先训练过的大型网络或集成转移到未经训练的小型网络中,即知识蒸馏。传递的知识在于:
- 输出概率的一致性(KD [10])
- 中间特征(AT [33]、AB [13]、FT [16]、OD [12]、FEED [22]、FitNet [24])
- 中间特征之间的相似性(FSP [31])的一致性。
每个方法不同的一致性的指标,包括输出概率之间的KL散度(KD [10],禁止[9]),回归与附加参数中间特性的映射(FitNet [24]),L1预测因素之间的距离(FT [16]),L1汇集注意之间的距离(AB[13]),L2纠正激活之间的距离(OD [12])。FEED [22]提出了教师网络集合的特征与未经训练的小网络之间的L1距离。CRD [29]提出了一个基于对比的目标,即在深度网络之间的表征空间中传递高阶依赖关系。
通过在一组未经训练的网络之间的一致性控制进行同步学习。最近,研究人员提出放宽预先训练的大型网络的要求,从一个未训练的网络池开始,并与网络的一致性控制同时学习。深度相互学习[35]表明,通过对输出概率的一致性控制,一群学生可以在整个训练过程中进行协作学习和相互教学。最近,FFT [15],ONE [36]和CL [28]提出了子网络分类器集合和每个子网络之间的一致性控制,其中每个子网络以在线知识蒸馏的方式相互教导。
无教师的正则化。在Tf-KD [32]中,引入了标签平滑正则化作为KD的虚拟教师模型,而不需要任何额外的对等网络。SD [30]提出使用早期时代的快照作为教师模型。这些工作仍然符合学生网络和参考目标之间的一致性,无论是手动设计还是从快照中选择。
在本研究中,我们提出了一个新的框架,将知识从教师网络转移到学生网络。超出了所使用的一致性控制范围在知识蒸馏和相互学习时,IE-KD进一步涉及到多样性控制。此外,我们的IE-KD方法支持一组网络之间的类似的相互学习,并取得了更好的性能。
3. Method
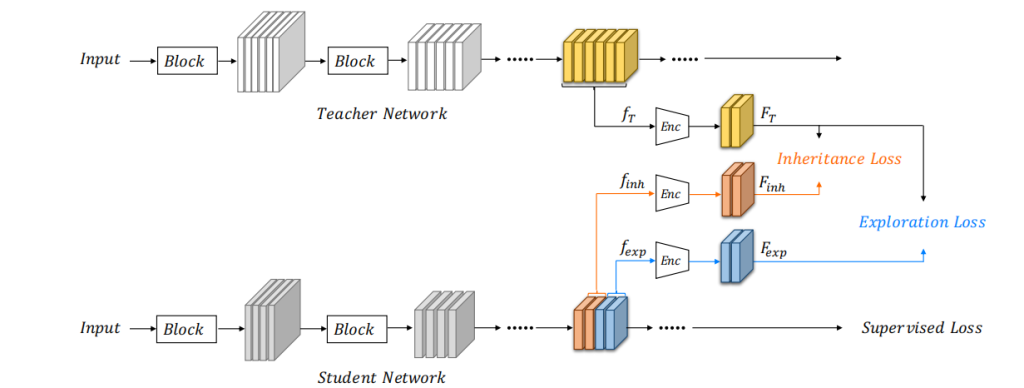
图2说明了我们的方法的框架。学生网络的特点分为两部分。其中一部分(用橙色表示)被训练成使用继承损失来模拟教师网络的紧凑特征,而另一部分(蓝色)被鼓励通过探索损失来学习不同于教师网络的新特征。监督任务(分类/检测)损失指导探索部分收敛到不同而有效的特征。总的来说,学生网络的训练对象是遗传损失和探索损失,以及传统的监督目标损失。
图2.IE-KD框架的概述。学生网络被分为两部分。其中一部分(橙色)通过一致性/遗传损失(相似性)继承了教师网络中由因素编码的紧凑而有效的表示,另一部分(蓝色)通过多样性/探索损失(不相似性)来生成不同的特征。监督任务(分类/检测)损失指导探索部分收敛到不同而有效的特征。
由于教师网络是经过预训练的,紧凑的特征也可以使用自动编码器预学习,我们将在第二讨论。3.1.然后,我们将在第二节中讨论IE-KD的细节。3.2,然后扩展到深度相互学习的方式。3.3.
3.1.紧凑的知识提取
我们将教师的特征表示为 ,将学生网络的继承部分和探索部分的特征分别表示为
,将学生网络的继承部分和探索部分的特征分别表示为 和
和 。测量这些特征之间的相似性/相似性的挑战在于它们通常有不同的形状和大小。为了解决这一问题,我们通过编码器将它们嵌入到同一维的共享潜在特征空间中,嵌入的特征分别由、和表示。我们在[16]中采用基于因子的嵌入模块,从教师网络的特定卷积块中提取知识。
。测量这些特征之间的相似性/相似性的挑战在于它们通常有不同的形状和大小。为了解决这一问题,我们通过编码器将它们嵌入到同一维的共享潜在特征空间中,嵌入的特征分别由、和表示。我们在[16]中采用基于因子的嵌入模块,从教师网络的特定卷积块中提取知识。
特别是采用由多个卷积层和反卷积层组成的自动编码器从教师网络中提取可转移因子。我们使用了三个卷积层和三个转置的卷积层。所有六层都使用3×3内核,步幅1,填充1,批量归一化,然后每六层。只有在第二次卷积时,输出特征映射的数量才被压缩为因子特征映射的数量。类似地,第二个转置的卷积层被调整大小,以匹配教师网络的特征映射。详细的体系结构可以在补充材料中找到。自动编码器通过常见的重建损失进行训练:

训练。首先对教师网络的因子自动编码器进行重构损失训练。然后,将学生网络中的因子编码器和主干网络与目标损失(分类、检测等)同时进行训练,继承损失和探索损失:
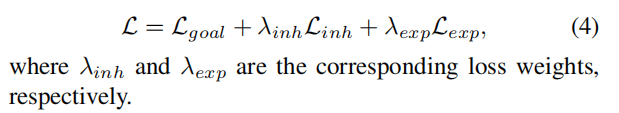









 是自动编码器的输出。
是自动编码器的输出。 的特征。直接推动学生模型模仿教师模型的特征,限制了学生模型学习未被发现的特征。因此,而不是对待和训练
的特征。直接推动学生模型模仿教师模型的特征,限制了学生模型学习未被发现的特征。因此,而不是对待和训练 ,并通过两个对应损失分别监管,一个继承损失
,并通过两个对应损失分别监管,一个继承损失 允许
允许 的设计目的是通过最小化
的设计目的是通过最小化 和
和
 归一化。
归一化。 、余弦距离(
、余弦距离( )、部分
)、部分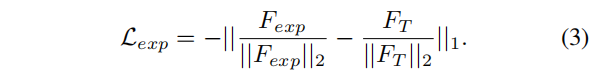
 ,这与
,这与 ),正交性测度(
),正交性测度( ),CKA [17],负的部分
),CKA [17],负的部分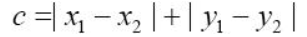
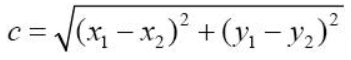
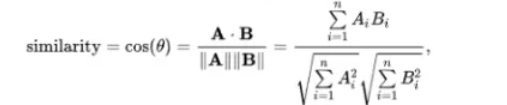
 由目标损失、重建损失、遗传损失、勘探损失四个部分组成:
由目标损失、重建损失、遗传损失、勘探损失四个部分组成: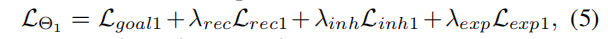
 、
、 和
和 分别为对应的损失权重。同样,网络Θ2的目标损失函数LΘ2可以计算为:
分别为对应的损失权重。同样,网络Θ2的目标损失函数LΘ2可以计算为: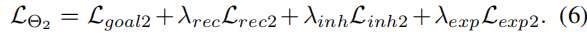



Comments | NOTHING